r2wars 2019
My writeup on the corewars-style challenge with a real-life instruction sets
September 08, 2019
You might have noticed I was at r2con 2019. This is my writeup for the r2wars 2019 challenge.
r2wars primer: a Core Wars-like game
In radare2, there's an intermediate language and VM called ESIL. It is used to emulate code, and supports many architectures. r2wars is built on top of r2's ESIL VM, so it supports any ESIL instruction sets, for example x86-32, mips-32 or arm-64.
Since it's based on Core Wars, in r2wars two opponents create "bots", short assembly programs, which are executed one after the other, in the same memory space, thanks to ESIL emulation. The goal is be the latest to survive; usually by wiping your opponent so that it executes and invalid instruction.
The ESIL vm is initialized with a 1024 bytes memory space plus a stack (more on that later), and the two opponents are placed randomly in this space. They are executed in round-robin: one after the other, one instruction each. A particularity is that you can have an opponent using a different architecture, since multi-architectures combats are supported: you only share the memory space, not the CPU state (registers). The server makes sure your memory does not overlap your opponents' at launch; afterwards, all bets are off. The CPU state is dumped after each instruction, to let the opponent run, and then restored before running the next instruction.
A contestant's bot looses when it attempts to:
- execute and invalid instruction
- write or read outside of the arena or stack
- execute instructions outside of the arena
- trigger an interrupt, trap, io error or exception.
The most reliable way to win is therefore to trigger one of the previous condition for the opponent by overwriting where it executes. But an other strategy could also be to survive until the other one suicides.
You send the source of your bot to the organizers ; the r2wars software is built in mono with a web interface, and automates the following tasks: it uses rasm2, the radare2 assembler to build your bot, it launches radare2, initializes ESIL, then launches 1v1 matches in a tournament, to determine the global ranking.
The challenge is ran over the two days of r2 con, with tournament runs at 10am, 2pm, and 5-6pm. So one has 5 runs to perfect their bot (with small prizes after each), and one final run for the final ranking.
Initial approach
I'm not a beginner to this challenge, since I participated last year; so my first idea was to simply to take my last bot, which ranked second last year, and submit it. Here is the commented arm64 assembly source:
adr x0, start ; get address of start label with pc-relative adr instruction
mov x3, 1008 ; put relocation address in x3 (just before the end of arena)
neg x5, x0 ; put some value looking like ffffff in x5 for writing
mov x4, x5 ; copy x5 to x4
ldp x1, x2, [x0] ; load code at start label into x1 and x2 (2 4-bytes instructions in each)
stp x1, x2, [x3] ; store code to relocation address
br x3 ; jump to the core loop at the relocation address
start:
stp x5, x4, [x3, -16]! ; decrement x3 by 16, then store 16 bytes of data (x5 and x4) in address pointed by x3
stp x5, x4, [x3, -16]! ; same write 16 bytes + pre-decrement
stp x5, x4, [x3, -16]! ; same write 16 bytes + pre-decrement
b start ; loop with relative backward jump
The core of this bot is 4 instructions, with a small setup to relocate the bot at the end of memory. Once the whole memory is overwritten, this bot makes a write to invalid address (x3 underflows) and dies.
I reused my workspace from last year meaning I could immediately do debug runs in radare2, but I had to reinstall the official mono builds (the only ones that work with r2wars) to run the game simulations.
I mildly tested my bot in radare2 (it worked, like last year), and submitted it immediately once my plane landed so that I could do the first round. I didn't want to spend to much time on it this year and wanted to follow more talks.
First roadblock
I got a message from the organizer asking me if I tested my bot. Hmmm, my spidey sense told me this wasn't a good sign. Of course, I tested it in radare2, it did overwrite the whole memory.
But as the first round came, something weird happened. It seemed like my bot committed suicide after only a few cycles. Did I miss something or trigger an exception ? I tried it again, and found I was able to reproduce the problem in r2wars, so I went to see the organizer to ask for help. It seemed the problem was only reproduced when running the bot in r2wars; the only difference with my testing script, is that r2wars needs to save and restore the CPU state after each instruction to execute each contestant in round-robin.
Very soon, skuater had a minimal reproducer of the issue, which helped pancake issue a fix. It was an underflow on restoration of the zero-register (x31), which instead of being ignored, triggered writes side-effects in x0, corrupting it.
I took some time for the fix to propagate to the machine used to run the tournament, so I missed the next two rounds of the day as well: not such a big issue since it gave me more time to follow the talks and socialize.
Reminescence
I took some time to try out an idea I had last year and for which I had submitted an ESIL patch: the single instruction bot, that consisted of only one instruction, that writes itself at the next address with a post-increment:
adr x0, start
ldr x1, [x0]
str x1, [x2]
br x3
start:
str x1, [x2, 4]!
str x1, [x2, 4]!
It still needs to write 8 bytes (two identical instructions), but it's effectively only using one at a time. It takes advantage of the fact that all registers (here x2 and x3) are initialized to zero.
While the bot did work, it wasn't very effective in my simulations, since the smaller footprint (4 bytes at a given time) wasn't worth much lower write throughput, which seems to be a core metric (but not sole, as we'll see later) in bot performance.
Insomnia
I didn't mean to, but it was bound to happen. I couldn't sleep, despite waking up at very early to catch my morning flight.
It occurred to me that I could simply workaround the radare2 issue by changing the register allocation in last year's bot: the bot was, after all, only using six out of thirty-one available registers on aarch64.
So I changed the bot to use different registers. It did work with a buggy radare2. But it wasn't enough.
I couldn't just keep testing against my simple bots, so I decided to do simulations against some of the best contestants from last year. Some had been published on github, so I downloaded them for simulation.
And they were still better. So I changed strategies... Along the way, I tried changing the loop to have one restore between each instruction, as well as delaying the relocation as much as possible, in order to beat other bots that would relocate at the end, like ik4ru5. In retrospect, the former (continuous restoration) was a mistake: it divided write throughput by 3, which is a hard blow to the bot performance.
Here, you can see how I duplicated the relocation code store instruction in order to delay the main loop as much as possible:
adr x10, start
mov x13, 1008
mov x14, x13
sub x5, x5, 1
mov x4, x5
ldp x11, x12, [x10]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
stp x11, x12, [x13]
br x13
start:
stp x11, x12, [x13]
stp x5, x4, [x14, -16]!
stp x11, x12, [x13]
b start
It did provide better performance against ik4ru5 and t_pageflt, but neither of them were participating in this year's r2 wars… So the result the next day on the first round wasn't really good:
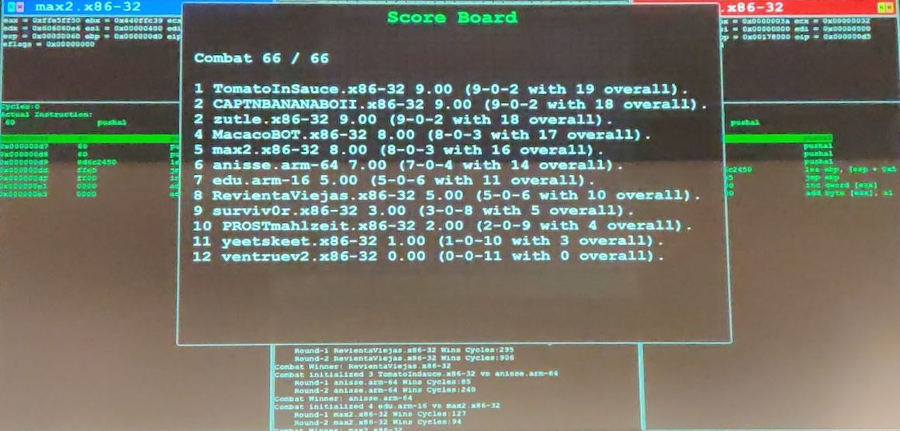
I ranked 6 out 12.
Intelligence
Luckily, I had decided to fully record this round (or as much as possible) in order to gather intel on how the other bots exactly worked. I just couldn't continue going blind since there was only two tournament runs, which wouldn't provide a good feedback loop for bot improvement.
I recorded videos and took a few photos in order to have a view on every participant, then decided to rewrite the top-5 bots from scratch. I first thought of using the assembly source, but since the r2 disassembler converts relative addresses (jumps, etc.) to absolute addresses, it would be hard, so I "simply" copied the hex code of each instruction into .hex directives for the assembler. It wasn't that simple though, as the quality was sometimes less than optimal:
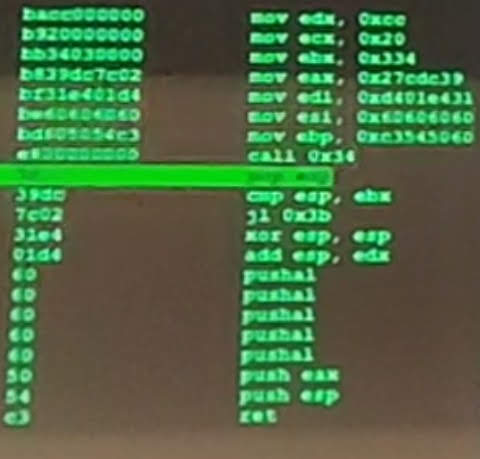
The challenge for next year would be to automate this task with OCR or Google Lens.
After a few typos, I finally had the code of the other top-5 contestants for this tournament iteration. I just had to hope that they wouldn't modify their bots too much before the next run.
Without surprise, they were very good, and were beating all the bots I had ever written (mostly). It might have stemmed from the pushal strategy that all the x86-32 employed: this instruction enables a throughput of 32 bytes per ESIL cycle, twice the 16 bytes per second of arm64 stp.
So I ran more simulations and iterated over the bot from last year.
Improvements
After a few iterations (not shown here), here is the bot that had a good win-rate in simulations (5 out of 5 adversaries). You can see it has many small changes:
adr x10, start ; 1
mov x2, 512+32 ; 2 - heuristic
mov x8, 0x180 ; 3 - heuristic
mov x9, 0x180 ; 4 - heuristic
ldp x11, x12, [x10], 16 ; 5
ldp x14, x15, [x10] ; 6
stp x11, x12, [x9], 16 ; 7
stp x14, x15, [x9] ; 8
br x8 ; 9
start: ; 10
and x2, x2, #0x3f0 ; 11 - looping with a modulo
stp x11, x12, [x2], 16 ; 12
stp x14, x15, [x2], 16 ; 13
stp x11, x12, [x2], 16 ; 14
stp x14, x15, [x2], 16 ; 15
stp x11, x12, [x2], 16 ; 16
stp x14, x15, [x2], 16 ; 17
b start ; 18
From line 2 you can see that something changed: I've split the main heuristic of relocating to the end of memory and writing from there into two: now the relocation address is at 384 bytes, and the start of writing address is 544.
The main loop (line 10-18) is now 8 instructions instead of 4, so it needs to be loaded with two ldp (line 5-6), and stored with two stp (line 7-8). Both used post-increment instead of pre-increment addressing.
In the loop, you see that we repeat the two stp in line (12-17): that's because we now write the bot itself all over memory, instead of 0xFF. I found this was just as efficient as 0xFF against x86 bots, and luckily, there was no arm64 participant this year !
Finally, this bot never dies by itself: as you can see the first instruction is an and in order to only keep the lower bits of the write address register x2. We need to make sure at the end of the of the loop that we finish with 0x400 in x2; this has a consequence of limiting the choices of the write-start heuristic (must be in the form n*96+64), and we absolutely need to use a post-increment instead of a pre-increment to detect the overflow before writing out of the arena.
Since this bot was unbeatable in my simulations (except by some arm64 bots with different heuristics) against "real" bots, I was very confident, and submitted my new iteration to the organizer, full of hubris:

But unfortunately, it wasn't the winner of the next round either, although it came close:
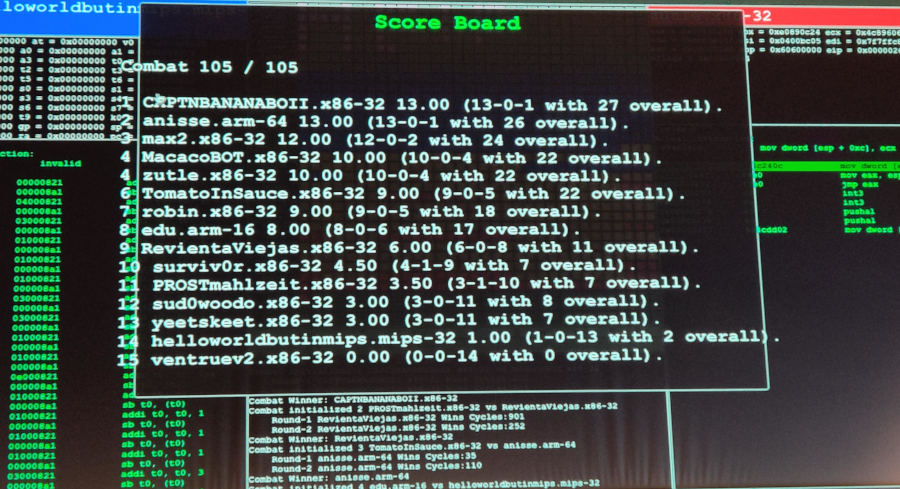
This was mostly because the CAP had improved his bot again, and we were now very close in terms of performance. I missed the beginning of this tournament round, so I don't know which which combat round was lost or why.
Interlude: funny bots spotted
During the first tournament round of the second day, we noticed something weird: an x86 bot was quite big, and took a lot of cycles of doing almost nothing:
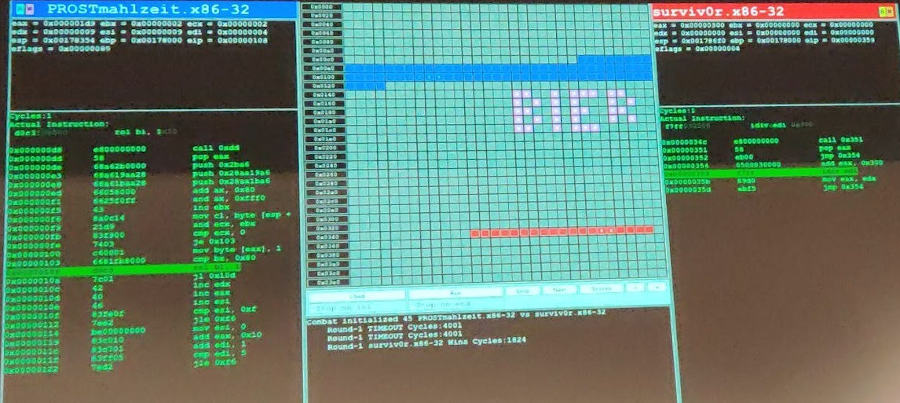
Turns out the bot was writing a message on screen, which took lots of cycles to write, because it was encoded in a bitmap that needed to be decoded. This bot had little chance of survival, in addition to triggering the timeout (4000 cycles), before finishing the full message, which I was told needed ~6000 cycles to complete. But a colleague of the author of PROSTmahlzeit was kind enough to submit the surviv0r bot so that it would get a chance to write its message. It was noticed by the organizers, and he got the prize he asked for :-)
Then, on the next tournament run, someone copied the idea, but implemented it in mips:
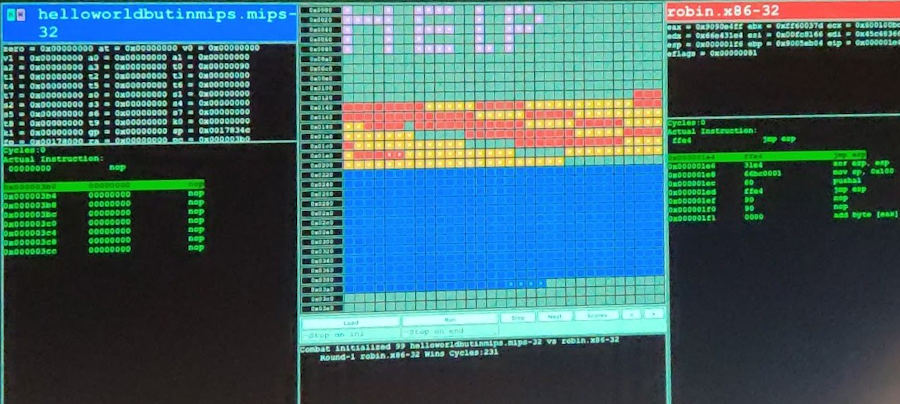
No bitmap though here since every address is hardcoded, making for a huge bot :-)
ARMv7 explorations
Over lunch, I was reminded of an ARMv7 instruction a colleague told me about: stmia and its ldmia counter part. These are used to store/load a set of registers with a post-increment of the address register. They're usually used for stack push/pop, fast memcpys, or context switching.
More importantly, it means you can reach a write throughput of 64 bytes per cycle (32 bits * 16 registers). So I modified my workspace to add support for arm32 bots and wrote a simple bot. Unfortunately, the post-increment in stmia did not work in ESIL.
Since I had decided to leave my bot as-is for the last round, I took instead some time to fix the stmia behaviour in ESIL, and submitted a pull request even with tests this time !
It's quite simple, and if you want to contribute to radare2, you can look at these patches, and do the same thing for stmib, stmdb, stmdb or ldmia variants. You can look at one of the ESIL introductory talks to understand how it works.
Final results and notes
Tips
Here's what I learned from the r2wars competition: Measure the average throughput per cycles (in my case, it was 12, just like last year). Measure the cycles to first write (7 cycles), and the length of your bot's main loop (32 bytes). Test against real bots; you can look at my repo for an overview, but for best results, try the ones you competed with in a previous round ! Once you know your competitors, you can tune the bot style (static or mobile), your start position, what type of data you write (are you writing valid x86 opcodes?), where you start writing it, etc.
Results
So the last round came and ran. I hadn't modified the bot since last time, as I wasn't sure what to improve, and I was thinking it best to leave well enough alone. Was it a good decision? Lets find out:
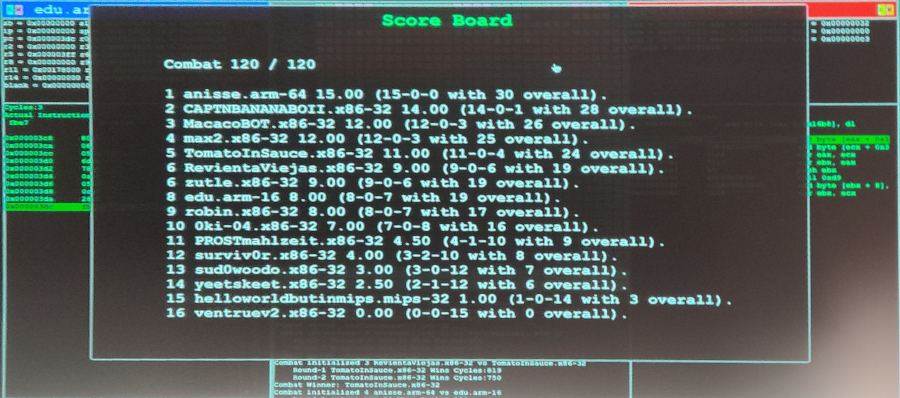
It turns out it was: I arrived first ! Of course it was luck since neither me nor the cap decided to modify their bot.
Note that the cap arrived in the top 3 of the CTF and also co-won the r2 PwnDebian challenge !
I also learned that I was the only one to have copied and run simulation with the competitors' bots, so the "intelligence" I described above gave me a bit of an advantage :-)
r2wars future
As we saw before, the write throughput is an important metric. And since ESIL isn't cycle accurate compared to the architectures it emulates, anyone adding instructions with higher throughput to the ESIL machine would have a huge advantage.
So the only logical conclusions is to move to SIMD instruction sets. Once NEON and AVX-512 are implemented, it will make for much faster bots. NEON VSTM can write 128 bytes in one instruction for example. We'll see if people plan r2wars by adding instructions to ESIL in advance :-) If it happens, the organizers might need to change the rules: have a bigger arena, ban some instructions, or make them take more cycles (i.e put a write throughput cycle cap in ESIL).
I want to thank the organizers for the incredible turn-around after I reported an issue. The second day, r2wars runs moved from Windows to MAC, they added color legends in the corners, and it ran and timeout-ed faster !