Keyboard layout adventures
Three bépo layout related stories
April 24, 2021
I've been using a french dvorak-like key layout, called bépo for about 13 years; sometimes, I need to hack things around to have it work everywhere, like when I wrote support for it android physical keyboards.
GPD Win Max Adaptation
I acquired recently a GPD Win Max, which is a descendant from netbooks crossed with a portable game console, and it quickly became my main computer (my old laptop was 10 years old, so it was indeed an upgrade).
While it's a very capable little device, it has a very condensed keyboard, which does not make it easy to use, especially when typing in bépo:

As you can see, it has been custom-designed for qwerty, and does not take into account other keyboard layouts. For example, there's no AltGr, and semicolon is hidden next to space. 60% keyboard owners would be right at home, if it were not for the lack of programmability of the layers.
In bépo, semicolon maps to N, which is a relatively common key. I decided to remap it like this, with bépo in mind:
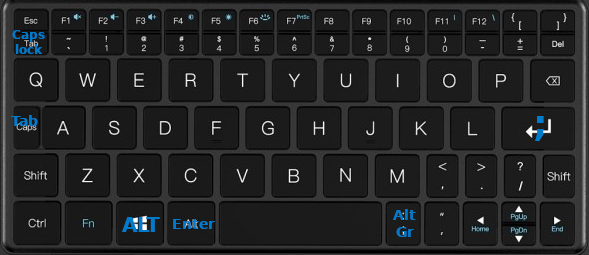
I replaced Enter with semicolon (N in bépo), and put Enter next to Space, taking inspiration from the split keyboards which better utilize thumbs for typing. I moved Alt on the Windows key, which I almost never use, and put AltGr on the semicolon key. Finally, I depend much more on Tab than Caps Lock, so I swapped the two keys.
To do this in Linux, once upon a time, one had to modify the xmodmap key, or create a custom xkb layout. Both of these would be less useful today: one still needs to type a passphrase before the X server starts (to unlock the disks), or to type stuff in wayland apps (which don't use X layout). Fortunately, starting udev 175, it's now possible to rearrange physical keys directly with udev. See for example this tutorial or this one in french (english here).
So I decided to re-order the keys (scancodes) at the udev level, to make use of the bépo layout as-is. The first step it to find which input device is the keyboard. I like looking into /proc/bus/input/devices. On x86 laptops, the keyboard is usually accessible through the i8042 device:
> cat /proc/bus/input/devices
[… cut …]
I: Bus=0011 Vendor=0001 Product=0001 Version=ab83
N: Name="AT Translated Set 2 keyboard"
P: Phys=isa0060/serio0/input0
S: Sysfs=/devices/platform/i8042/serio0/input/input4
U: Uniq=
H: Handlers=sysrq kbd leds event4
B: PROP=0
B: EV=120013
B: KEY=402000000 3803078f800d001 deffffdfffefffff fffffffffffffffe
B: MSC=10
B: LED=7
[… cut …]
It says here its sysfs device is /devices/platform/i8042/serio0/input/input4. I want to know how to match this device with udev, so I run:
> sudo udevadm info /sys/devices/platform/i8042/serio0/input/input4
P: /devices/platform/i8042/serio0/input/input4
L: 0
E: DEVPATH=/devices/platform/i8042/serio0/input/input4
E: PRODUCT=11/1/1/ab83
E: NAME="AT Translated Set 2 keyboard"
E: PHYS="isa0060/serio0/input0"
E: PROP=0
E: EV=120013
E: KEY=402000000 3803078f800d001 deffffdfffefffff fffffffffffffffe
E: MSC=10
E: LED=7
E: MODALIAS=input:b0011v0001p0001eAB83-e0,1,4,11,14,k71,72,73,74,75,76,77,79,7A,7B,7C,7E,7F,80,8C,8E,8F,9B,9C,9D,9E,9F,A3,A4,A5,A6,AC,AD,B7,B8,B9,D9,E2,ram4,l0,1,2,sfw
E: SUBSYSTEM=input
E: USEC_INITIALIZED=12327754
E: ID_INPUT=1
E: ID_INPUT_KEY=1
E: ID_INPUT_KEYBOARD=1
E: ID_BUS=i8042
E: ID_SERIAL=noserial
E: ID_PATH=platform-i8042-serio-0
E: ID_PATH_TAG=platform-i8042-serio-0
E: ID_FOR_SEAT=input-platform-i8042-serio-0
E: TAGS=:seat:
The interesting line here is the MODALIAS. I'll use the input:b0011v0001p0001eAB83… line to match precisely this keyboard, and ask udev to swap its keys. In order to do this, I follow the tutorial I linked earlier and create a file in /etc/udev/hwdb.d:
> cat /etc/udev/hwdb.d/98-gpd-keyboard.hwdb
evdev:input:b0011v0001p0001eAB83*
KEYBOARD_KEY_db=leftalt # Alt on windows
KEYBOARD_KEY_38=enter # enter on Alt
KEYBOARD_KEY_1c=semicolon # n on enter
KEYBOARD_KEY_27=rightalt # AltGr on n
KEYBOARD_KEY_3a=tab # swap caps lock and tab
KEYBOARD_KEY_0f=capslock # swap tab and caps lock
Then update the udev hwdb:
> sudo udevadm hwdb --update
and re-trigger rules for this device:
> sudo udevadm trigger /dev/input/event4
Note that I use the device node instead of the sysfs path for the trigger: /dev/input/event4.
Yubikey OTP with bépo
A Yubikey used in OTP mode will send keys that have been selected to be a common "subset" between common western layouts: qwerty, azerty, qwertz, etc. Of course, no key is at the same place in bépo, so this this doesn't work.
Using the exact same methodology as before, it's possible to use a Yubikey (in OTP mode) without changing the keymap to qwerty/azerty before use. Here is the file I now have on multiple machines:
> cat /etc/udev/hwdb.d/99-yubi-bepo.hwdb
# Scancodes: https://gist.github.com/MightyPork/6da26e382a7ad91b5496ee55fdc73db2
# Yubikey character list: https://blog.inf.ed.ac.uk/project313/2016/01/29/modified-hexadecimal-encoding-a-k-a-modhex/
# keycodes: /usr/include/linux/input-event-codes.h
# tutorial: EN https://yulistic.gitlab.io/2017/12/linux-keymapping-with-udev-hwdb/ FR https://www.vinc17.net/unix/xkb.fr.html
evdev:input:b0003v1050p0407e0110*
KEYBOARD_KEY_70005=q # c
KEYBOARD_KEY_70006=h # b
KEYBOARD_KEY_70007=i # d
KEYBOARD_KEY_70008=f # e
KEYBOARD_KEY_70009=slash # f
KEYBOARD_KEY_7000a=comma # g
KEYBOARD_KEY_7000b=dot # h
KEYBOARD_KEY_7000c=d # i
KEYBOARD_KEY_7000d=p # j
KEYBOARD_KEY_7000e=b # k
KEYBOARD_KEY_7000f=o # l
KEYBOARD_KEY_70011=semicolon # n
KEYBOARD_KEY_70015=l # r
KEYBOARD_KEY_70017=j # t
KEYBOARD_KEY_70018=s # u
KEYBOARD_KEY_70019=u # v
Fun fact: it wouldn't be needed if we had a way to always use a given keymap (say, qwerty) for a device that sends keys like this. And there is such a way, kinda: the systemd developers added such a feature in hwdb 5 years ago, but it still isn't honored by desktop environments.
Inability to type with bépo AFNOR in a Linux console
In 2015, a french standardization process was started to make new and homogeneous french keyboard layouts. In 2019, a new AZERTY layout was standardized. In addition to this, years of community efforts (of which I had nothing to do with, but I saw the countless mailing list messages) helped standardize at the same time a new BÉPO layout, bépo 1.1, or bépo AFNOR.
It's almost the same as bépo 1.0, so moving to it was pretty painless. It was also integrated relatively quickly in Linux distributions via the xkeyboard-config project (although it does not have all the compose goodies, which are mostly for exotic characters).
While it was painless to use in desktop environments, this layout did not load during boot in console mode, which plymouth uses for querying the disk passphrase. Since it did not load, the fallback was to an unconfigured qwerty layout, which is not the most comfortable to type passphrase if you're not used to it. It was reported to Debian, but the issue is identical in Fedora or Ubuntu. After being annoyed for a few months, I took some time to try to fix it.
Virtual TTY keyboard layouts are first converted by ckbcomp from the xkb format, and then loaded into the kernel by kbd. So I had a look at kbd, and after messing around, I sent the following patch upstream:
Subject: [PATCH] src/libkeymap: add support for parsing more unicode values
The auto-generated (with ckbcomp) file fr-bepo_afnor did not load (even
partially), because of an U+1f12f (copyleft symbol) that is wrongly
parsed, generating this error message:
too many (160) entries on one line
Fix libkeymap so that the keymap can be parsed, even if the offending
character won't be loaded because of the ushort limitation of the
kb_value KDSKBENT uapi.
It's better to have the keymap partially loaded than not at all.
[… cut …]
diff --git a/src/libkeymap/analyze.l b/src/libkeymap/analyze.l
Hex 0[xX][0-9a-fA-F]+
-Unicode U\+([0-9a-fA-F]){4}
+Unicode U\+([0-9a-fA-F]){4,6}
Literal [a-zA-Z][a-zA-Z_0-9]*
[… cut …]
- if (yylval->num >= 0xf000) {
+ if (yylval->num >= 0x10ffff) {
ERR(yyextra, _("unicode keysym out of range: %s"),
As you can see, a single symbol '🄯' couldn't be loaded because its unicode value is 5 hex characters instead of 4, and is bigger than the max of 0xf000. So I made the lexer regex recognize longer unicode characters (up to 6, the max allowed), and made the range go to the current unicode limit as well.
Only there is one issue: it was simply incorrect. While it worked on my machine, it was just the wrong thing to do, as you can see with this answer from Alexey Gladkov, kbd's maintainer:
Nop. Partially keymap loading is very dangerous. You can get a completely unusable console. The libkeymap shouldn't break the console if it is known in advance that the keymap is not correct. You should fix ckbcomp so that it generates the correct keymap.
This is because the linux kernel simply does not support loading unicode symbols greater than 0xf000 with the KDSETKEYCODE ioctl, because the ABI uses 16-bits values. There are probably other reasons internal to the kernel console keyboard or font handling, but I haven't dug into why.
So I changed my patch to kbd show a better error message instead
Subject: [PATCH] src/libkeymap: better error message on unsupported unicode
value
The auto-generated (with ckbcomp) file fr-bepo_afnor did not load (even
partially), because of an U+1f12f (copyleft symbol) that is wrongly
parsed, generating this error message:
too many (160) entries on one line
Fix libkeymap so that the symbol can be parsed, and later generate a
better error message:
unicode keysym out of range: U+1f12f
At least users will know what is wrong with their keymap.
[… cut …]
diff --git a/src/libkeymap/analyze.l b/src/libkeymap/analyze.l
Hex 0[xX][0-9a-fA-F]+
-Unicode U\+([0-9a-fA-F]){4}
+Unicode U\+([0-9a-fA-F]){4,6}
Literal [a-zA-Z][a-zA-Z_0-9]*
[… cut …]
And then started looking at ckbcomp a huge perl script, part of the console-setup project, that is used to do the conversion from xkb format, to a format understandable by kbd.
It already had provisions for removing unknown symbols with the internal $voidsymbol, which I used to replace any character outside of the range supported by Linux.
Here is the patch I sent upstream:
Subject: [PATCH] ckbcomp: fix fr-bepo_afnor conversion by skipping unsupported symbols
Some X keymaps, including fr bepo_afnor use unicode symbols greater than
0xf000; for example the copy left symbol U+1f12f.
These values aren't supported by the linux kernel, so loadkeys won't be
able to load them, or even parse the value.
Skip those symbols to generate valid keymaps.
Fixes: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=968195
Signed-off-by: Anisse Astier <anisse@astier.eu>
---
Keyboard/ckbcomp | 3 +++
1 file changed, 3 insertions(+)
diff --git a/Keyboard/ckbcomp b/Keyboard/ckbcomp
index e638a24..c3003e6 100755
--- a/Keyboard/ckbcomp
+++ b/Keyboard/ckbcomp
@@ -3815,6 +3815,9 @@ sub uni_to_legacy {
return $voidsymbol;
}
} else {
+ if ($uni >= 0xf000) { # Linux limitation
+ return $voidsymbol;
+ }
return 'U+'. sprintf ("%04x", $uni);
}
}
Unfortunately, I've yet to hear from the console-setup maintainers on whether this is correct or not. I'll update this article if the situation changes. In the meantime, I was able to scratch my itch, and I can now type my disk unlock passphrase in plymouth with the bépo 1.1 key layout.
Update: the bug has been fixed on Oct 31st in console-setup 1.206! It made it to Fedora 36, but not Ubuntu 22.04 :-(