Performance lessons of implementing lbzcat in Rust
A small benchmarking adventure
July 24, 2025
This was originally published as a thread on Mastodon.
For fun I implemented lbzip2's lbzcat (parallel bzip2 decompression) clone in rust, using the bzip2 crate.
Baseline: bzip2 vs bzip2-rs
First, let's look at the baseline. The Trifecta Tech Foundation recently claimed that bzip2-rs had faster decompression than libbzip2's original C implementation. Is this true? Well, it depends...
I'll do benchmarks using my own bzcat and comparing that with bzip3's original bzcat. All running on an M1 laptop running #AsahiLinux. The M1 CPU has both performance and efficiency cores. We'll run the benchmark on both, using hyperfine to do the comparisons.
So, let's start with the most obvious, the performance cores; they make the most sense for a CPU-intensive task; on my systems those are CPU 4-7. We can see here that the promise of the Trifecta Foundation holds, as the rust implementation is about 4% faster.
![$ taskset -c 7 hyperfine -N -L program bzcat,./target/release/bzcat -n "original-bzcat" -n "rust-bzcat" "{program} readmes.tar.bz2 ./sample2.bz2 ./re2-exhaustive.txt.bz2"
Benchmark 1: original-bzcat
Time (mean ± σ): 632.8 ms ± 29.2 ms [User: 628.4 ms, System: 2.4 ms]
Range (min … max): 587.5 ms … 660.0 ms 10 runs
Benchmark 2: rust-bzcat
Time (mean ± σ): 608.7 ms ± 30.2 ms [User: 605.8 ms, System: 0.9 ms]
Range (min … max): 562.1 ms … 633.6 ms 10 runs
Summary
rust-bzcat ran
1.04 ± 0.07 times faster than original-bzcat](images/lbzip2-rs/01-bzcat-firestorm.png)
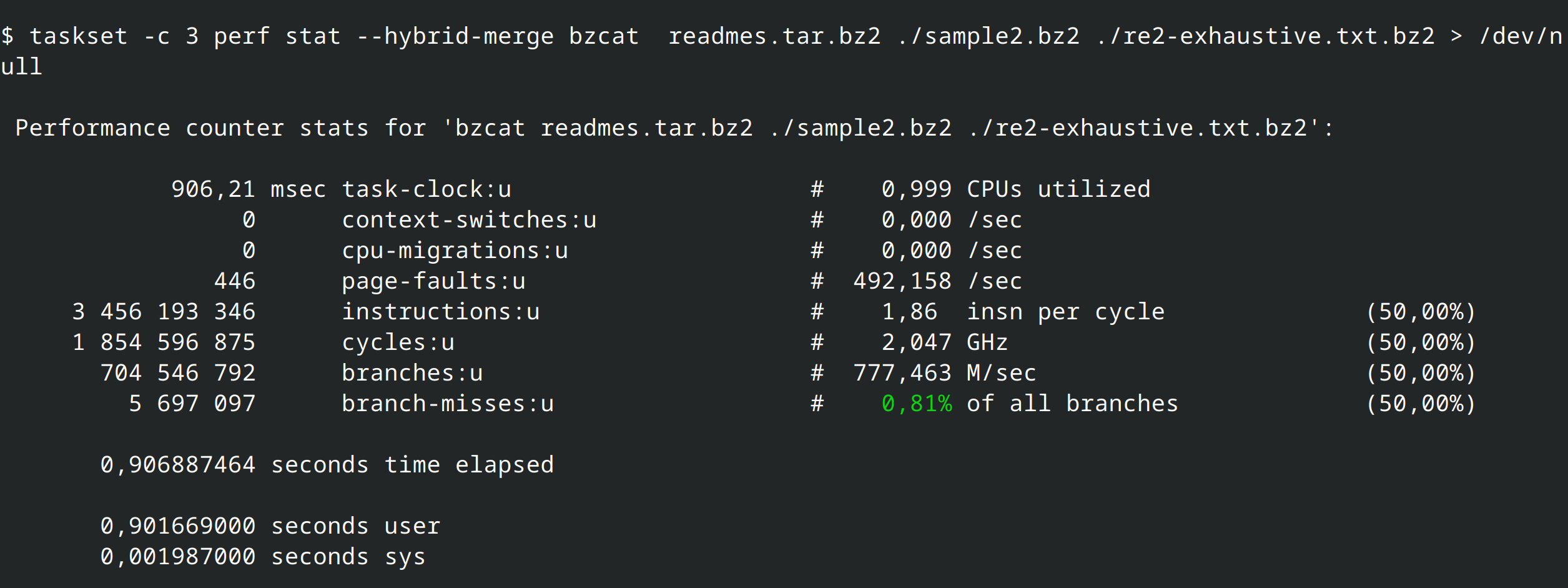
What about the efficiency cores? (0-3 on my system); well, everything breaks down on those CPUs. Both implementations are now much closer in performance !
![$ taskset -c 3 hyperfine -N -L program bzcat,./target/release/bzcat -n "original-bzcat" -n "rust-bzcat" "{program} readmes.tar.bz2 ./sample2.bz2 ./re2-exhaustive.txt.bz2"
Benchmark 1: original-bzcat
Time (mean ± σ): 927.7 ms ± 23.5 ms [User: 919.2 ms, System: 3.4 ms]
Range (min … max): 904.9 ms … 955.3 ms 10 runs
Benchmark 2: rust-bzcat
Time (mean ± σ): 937.2 ms ± 22.0 ms [User: 929.4 ms, System: 3.2 ms]
Range (min … max): 905.5 ms … 959.4 ms 10 runs
Summary
original-bzcat ran
1.01 ± 0.03 times faster than rust-bzcat](images/lbzip2-rs/02-bzcat-icestorm.png)
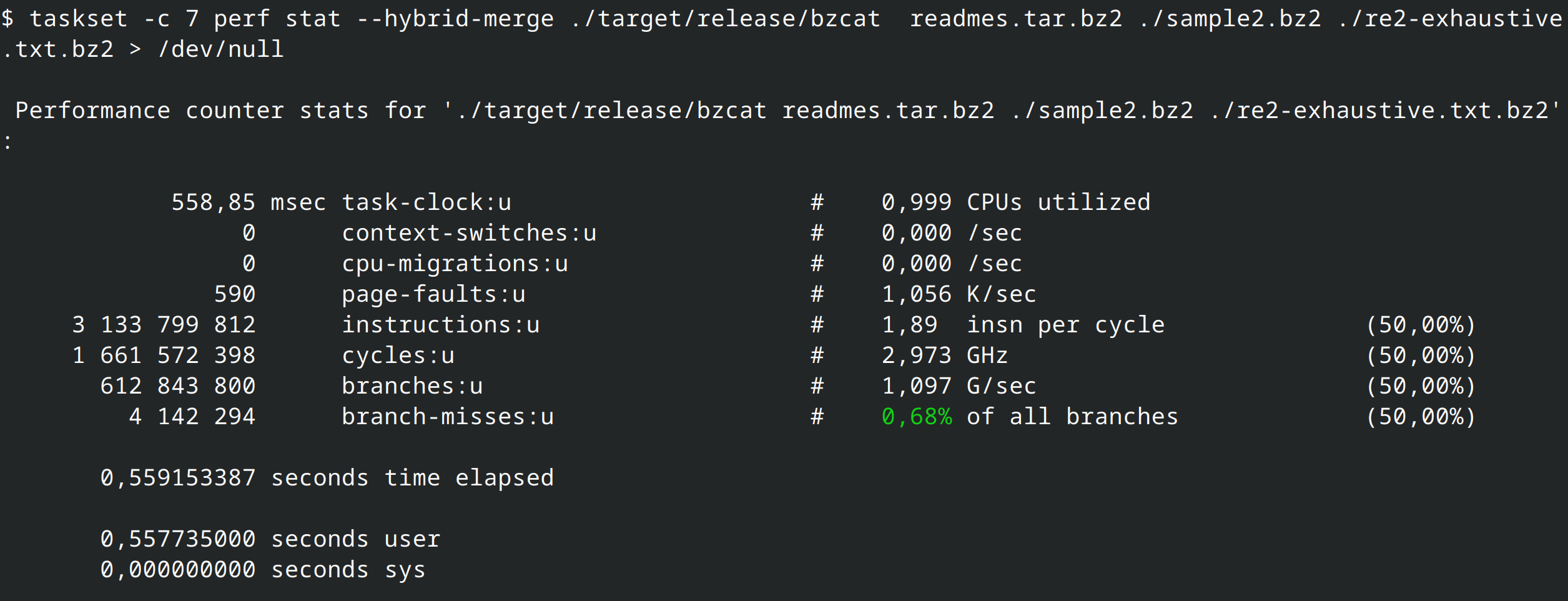
But why? Let's see what perf stat has to say: the Rust version has less instructions, but with much less IPC (Instruction-per-clock); the Rust version also has less branches and misses in general.
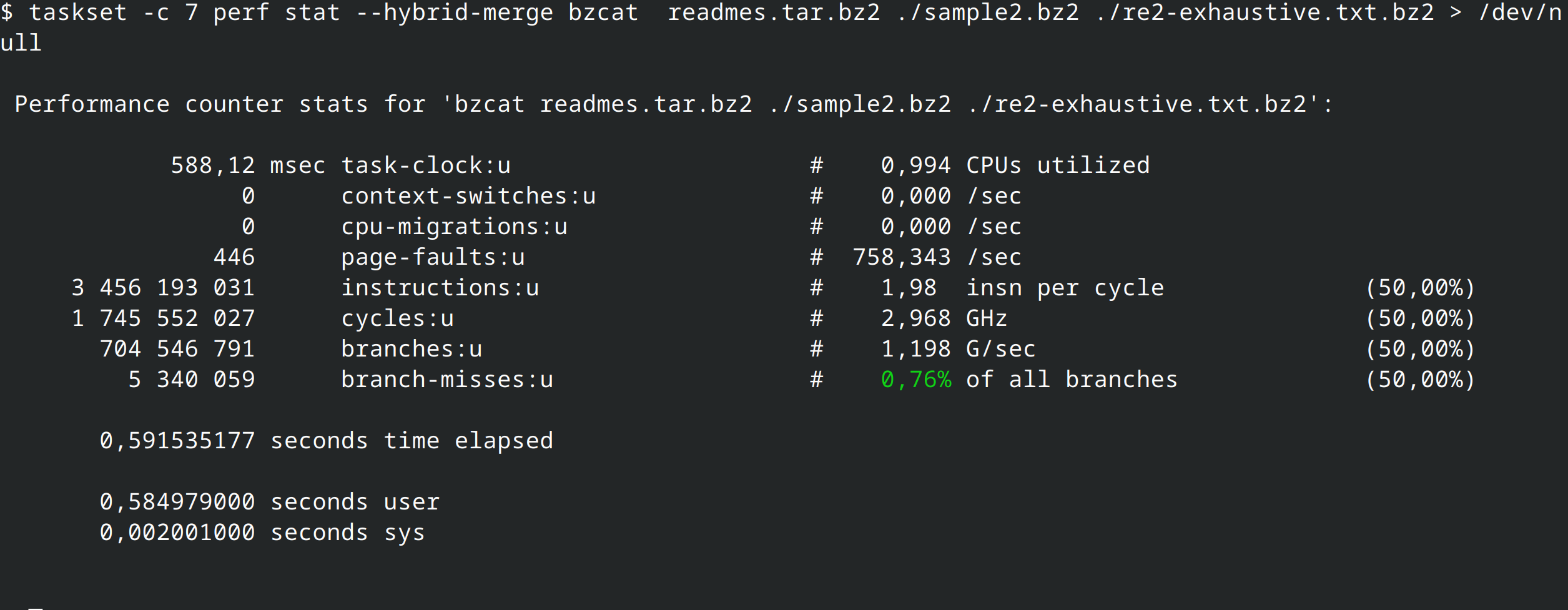
On the efficiency cores, we see that worse IPC and branch prediction of the Rust version give the advantage to the C version.
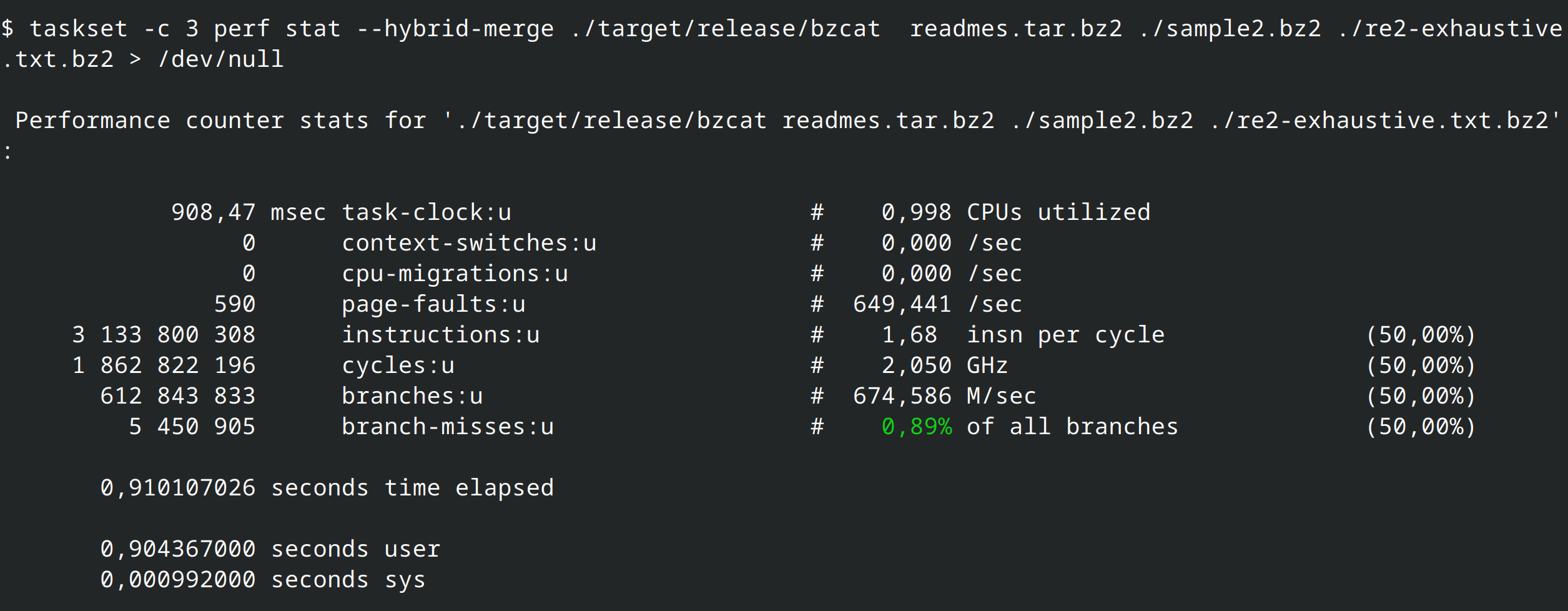
That gives us our baseline: bzip2 (in C) vs bzip2 (in Rust). But is it a fair enough comparison?
lbzip2 enters the chat
I mentioned initially that I was implementing an lbzip2 "clone" (mostly a PoC for the decompression part). lbzip2 is an other program (a C binary, without a library), that can compress and decompress bzip2 files in parallel. Surely it should be slower than bzip2 since it has the parallel management overhead? Let's have a look!
![$ taskset -c 7 hyperfine -N -L program bzcat,lbzcat -n "{program}" "{program} ./sample2.bz2 ./re2-exhaustive.txt.bz2"
Benchmark 1: bzcat
Time (mean ± σ): 587.0 ms ± 30.5 ms [User: 581.4 ms, System: 3.8 ms]
Range (min … max): 539.8 ms … 611.2 ms 10 runs
Benchmark 2: lbzcat
Time (mean ± σ): 693.5 ms ± 4.6 ms [User: 686.4 ms, System: 4.3 ms]
Range (min … max): 686.2 ms … 700.4 ms 10 runs
Summary
bzcat ran
1.18 ± 0.06 times faster than lbzcat](images/lbzip2-rs/07-lbzcat-firestorm-slow.png)
![$ taskset -c 3 hyperfine -N -L program bzcat,lbzcat -n "{program}" "{program} ./sample2.bz2 ./re2-exhaustive.txt.bz2"
Benchmark 1: bzcat
Time (mean ± σ): 840.3 ms ± 21.7 ms [User: 831.1 ms, System: 3.7 ms]
Range (min … max): 813.8 ms … 861.7 ms 10 runs
Benchmark 2: lbzcat
Time (mean ± σ): 1.637 s ± 0.013 s [User: 1.617 s, System: 0.011 s]
Range (min … max): 1.623 s … 1.664 s 10 runs
Summary
bzcat ran
1.95 ± 0.05 times faster than lbzcat](images/lbzip2-rs/08-lbzcat-icestorm-slow.png)
Indeed, bzip2 is faster than lbzip2. Between 18% and 95% faster!
While running this, I discovered something. lbzip2's detection of the cores it can run on is... lacking: it uses the number of globally online cpu cores instead the syscall sched_getaffinity for the current process, so let's manually limit the number of processing threads:
![$ taskset -c 7 hyperfine -N -L program bzcat,"lbzcat -n1" -n "{program}" "{program} ./sample2.bz2 ./re2-exhaustive.txt.bz2"
Benchmark 1: bzcat
Time (mean ± σ): 576.1 ms ± 34.1 ms [User: 572.1 ms, System: 2.3 ms]
Range (min … max): 539.1 ms … 613.2 ms 10 runs
Benchmark 2: lbzcat -n1
Time (mean ± σ): 535.5 ms ± 1.1 ms [User: 532.7 ms, System: 1.3 ms]
Range (min … max): 534.7 ms … 537.6 ms 10 runs
Summary
lbzcat -n1 ran
1.08 ± 0.06 times faster than bzcat](images/lbzip2-rs/09-lbzcat-n1-firestorm.png)
![$ taskset -c 3 hyperfine -N -L program bzcat,"lbzcat -n1" -n "{program}" "{program} ./sample2.bz2 ./re2-exhaustive.txt.bz2"
Benchmark 1: bzcat
Time (mean ± σ): 839.7 ms ± 24.9 ms [User: 830.7 ms, System: 5.1 ms]
Range (min … max): 809.2 ms … 868.9 ms 10 runs
Benchmark 2: lbzcat -n1
Time (mean ± σ): 808.6 ms ± 22.1 ms [User: 801.6 ms, System: 3.0 ms]
Range (min … max): 790.6 ms … 850.6 ms 10 runs
Summary
lbzcat -n1 ran
1.04 ± 0.04 times faster than bzcat](images/lbzip2-rs/10-lbzcat-n1-icestorm.png)
lbzip2 is now always faster, between 4% and 8%.
But wait, there is more. lbzip2 also does compression, and does so in a way that optimizes decompression. If we use a file compressed by lbzip2, it can be even faster, even on a single thread: up to 125% faster:
![$ taskset -c 7 hyperfine -N -L program bzcat,"lbzcat -n1" -n "{program}" "{program} readmes.tar.bz2"
Benchmark 1: bzcat
Time (mean ± σ): 82.2 ms ± 16.0 ms [User: 80.8 ms, System: 0.9 ms]
Range (min … max): 50.1 ms … 111.6 ms 58 runs
Benchmark 2: lbzcat -n1
Time (mean ± σ): 36.6 ms ± 0.3 ms [User: 35.7 ms, System: 0.6 ms]
Range (min … max): 36.3 ms … 38.8 ms 82 runs
Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet system without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
Summary
lbzcat -n1 ran
2.25 ± 0.44 times faster than bzcat](images/lbzip2-rs/11-lbzcat-n1-firestorm-fast.png)
![$ taskset -c 3 hyperfine -N -L program bzcat,"lbzcat -n1" -n "{program}" "{program} readmes.tar.bz2"
Benchmark 1: bzcat
Time (mean ± σ): 112.6 ms ± 21.9 ms [User: 109.7 ms, System: 1.7 ms]
Range (min … max): 87.5 ms … 135.7 ms 34 runs
Benchmark 2: lbzcat -n1
Time (mean ± σ): 64.3 ms ± 8.5 ms [User: 61.4 ms, System: 2.1 ms]
Range (min … max): 61.5 ms … 107.9 ms 47 runs
Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet system without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
Summary
lbzcat -n1 ran
1.75 ± 0.41 times faster than bzcat](images/lbzip2-rs/12-lbzcat-n1-icestorm-fast.png)
lbzcat-rs
What about my implementation of lbzcat? It was designed to work with files generated by lbzip2: it does not work on some files compressed by bzip2, and silently produces incorrect output (!). So we'll limit benchmarking to files produced by lbzip2.
![$ taskset -c 7 hyperfine -N -L program bzcat,"lbzcat -n1",./target/release/lbzcat "{program} readmes.tar.bz2"Benchmark 1: bzcat readmes.tar.bz2
Time (mean ± σ): 83.5 ms ± 13.7 ms [User: 82.3 ms, System: 0.7 ms]
Range (min … max): 51.3 ms … 105.0 ms 58 runs
Benchmark 2: lbzcat -n1 readmes.tar.bz2
Time (mean ± σ): 37.7 ms ± 2.4 ms [User: 36.6 ms, System: 0.9 ms]
Range (min … max): 36.3 ms … 47.2 ms 63 runs
Warning: The first benchmarking run for this command was significantly slower than the rest (47.2 ms). This could be caused by (filesystem) caches that were not filled until after the first run. You should consider using the '--warmup' option to fill those caches before the actual benchmark. Alternatively, use the '--prepare' option to clear the caches before each timing run.
Benchmark 3: ./target/release/lbzcat readmes.tar.bz2
Time (mean ± σ): 54.4 ms ± 2.3 ms [User: 53.3 ms, System: 0.8 ms]
Range (min … max): 48.1 ms … 57.5 ms 62 runs
Summary
lbzcat -n1 readmes.tar.bz2 ran
1.44 ± 0.11 times faster than ./target/release/lbzcat readmes.tar.bz2
2.22 ± 0.39 times faster than bzcat readmes.tar.bz2](images/lbzip2-rs/13-lbzcat-n1-rust-firestorm.png)
![$ taskset -c 3 hyperfine -N -L program bzcat,"lbzcat -n1",./target/release/lbzcat "{program} readmes.tar.bz2"
Benchmark 1: bzcat readmes.tar.bz2
Time (mean ± σ): 116.3 ms ± 22.7 ms [User: 113.1 ms, System: 1.7 ms]
Range (min … max): 86.8 ms … 147.4 ms 34 runs
Benchmark 2: lbzcat -n1 readmes.tar.bz2
Time (mean ± σ): 62.3 ms ± 1.2 ms [User: 59.0 ms, System: 2.4 ms]
Range (min … max): 61.1 ms … 68.8 ms 47 runs
Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet system without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
Benchmark 3: ./target/release/lbzcat readmes.tar.bz2
Time (mean ± σ): 109.6 ms ± 17.4 ms [User: 106.0 ms, System: 2.4 ms]
Range (min … max): 95.2 ms … 143.5 ms 30 runs
Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet system without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
Summary
lbzcat -n1 readmes.tar.bz2 ran
1.76 ± 0.28 times faster than ./target/release/lbzcat readmes.tar.bz2
1.87 ± 0.37 times faster than bzcat readmes.tar.bz2](images/lbzip2-rs/14-lbzcat-n1-rust-icestorm.png)
Overall, my Rust implementation (using the bzip2-rs crate) is (much) slower than lbzip2, and faster than bzip2. For some reasons, it also sees huge performance boost on performance cores, most likely due to better IPC and branch prediction.
In parallel
We've been running benchmarks on single CPU cores since the start. What if we unleash the parallel mode? Here are the results:
![$ hyperfine -N -L program bzcat,lbzcat,./target/release/lbzcat "{program} readmes.tar.bz2"
Benchmark 1: bzcat readmes.tar.bz2
Time (mean ± σ): 74.8 ms ± 19.1 ms [User: 73.5 ms, System: 0.6 ms]
Range (min … max): 56.0 ms … 104.3 ms 50 runs
Benchmark 2: lbzcat readmes.tar.bz2
Time (mean ± σ): 29.3 ms ± 3.6 ms [User: 64.7 ms, System: 2.7 ms]
Range (min … max): 16.1 ms … 40.1 ms 85 runs
Benchmark 3: ./target/release/lbzcat readmes.tar.bz2
Time (mean ± σ): 44.1 ms ± 2.8 ms [User: 117.7 ms, System: 2.7 ms]
Range (min … max): 32.9 ms … 47.7 ms 63 runs
Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet system without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
Summary
lbzcat readmes.tar.bz2 ran
1.51 ± 0.21 times faster than ./target/release/lbzcat readmes.tar.bz2
2.56 ± 0.73 times faster than bzcat readmes.tar.bz2](images/lbzip2-rs/15-lbzcat-parallel-rust.png)
lbzip2 is still much faster on the 8 cores (2.56x times than bzcat); my implementation holds up fine, but is only 80% faster than bzip2, while also running on 8 cores.
On bigger files though, it starts to pay off:
![$ hyperfine -m 1 -N -L program bzcat,./target/release/lbzcat,lbzcat "{program} contains-Q484170.json.bz2"
Benchmark 1: bzcat contains-Q484170.json.bz2
Time (abs ≡): 27.194 s [User: 27.055 s, System: 0.071 s]
Benchmark 2: ./target/release/lbzcat contains-Q484170.json.bz2
Time (abs ≡): 4.237 s [User: 33.433 s, System: 0.188 s]
Benchmark 3: lbzcat contains-Q484170.json.bz2
Time (abs ≡): 3.513 s [User: 26.614 s, System: 0.165 s]
Summary
lbzcat contains-Q484170.json.bz2 ran
1.21 times faster than ./target/release/lbzcat contains-Q484170.json.bz2
7.74 times faster than bzcat contains-Q484170.json.bz2](images/lbzip2-rs/16-lbzcat-parallel-rust-big.png) with up to 6.3x faster for my Rust lbzcat, while lbzip2 can go to 7.7x.
with up to 6.3x faster for my Rust lbzcat, while lbzip2 can go to 7.7x.
That's it for the benchmarking! You can find my lbzcat in Rust implementation here; it's very much PoC-quality code, so use at our own risks! I chose to manually spawn threads instead of using rayon or an async runtime; there are other things I'm not proud of, like busy-waiting instead of condvar for example.
lbzip2 internally implements a full task-scheduling runtime, and splits tasks at a much smaller increments; it supports bit-aligned blocks (that are standard in bzip2 format), while my Rust implementation puposefully doesn't: I wanted to rely on the bzip2 crate that only supports byte-aligned buffers, and keep code simple (which I failed IMHO).