Testing a NAS hard drive over FTP
Because SMART is too simple.
December 20, 2013
So I have this NAS made by my ISP, that does a lot of things; but recently, I started having issues with its behavior. Recorded TV shows had lag/jitter while replaying, and the same happened with other types of videos I put on it. I narrowed it down to the hard drive, which was sometime providing read speeds of less than 300 KiB/s. I cannot open it to test the hard drive more thoroughly, using mhdd or ATA SMART tests. I'll have to innovate a little.
In this post, in the form of an ipython3 notebook(source), I'm going to test the hard drive over ftp, by doing a full hard drive fill, and then a read. I'm going to :
- measure the read and write speed to see if the problem is still present after I formated it.
- make sure what I wrote is the same as what I read
- I'll have to make sure that I can generate data fast enough
- And I'll try to make the data look "random" so that I don't stumble upon some compression in the FTP -> fs > hard drive chain.
If everything is well I'll just get on with it: formatting the hard drive fixed the issue. Otherwise, it's might be a hardware problem, and I'll have to exchange it.
To generate the data, I'll use an md5 hash for its nice output which looks fairly random, and this is very hard to compress. I chose md5 because it's fast. I'll use a sequential index as the input so that it's deterministic and I can fairly easily re-generate the input data for comparison.
import hashlib
h = hashlib.new("md5")
#Generate a deterministic hash
def data(i):
h.update(bytes(i))
return h.digest()
import time
def testdata():
n = 10000
size = h.digest_size
start = time.clock()
for i in range(n):
data(i)
end = time.clock()
speed = n*size/(end-start)
print("We generated %d bytes in %f s %d B/s"%(n*size, end-start, speed))
testdata()
We generated 160000 bytes in 1.610000 s 99378 B/s
Ouch. I use a slow machine, and it's far from the at least 60MiB/s I need to thoroughly test the hard drive. Let's see if I can find a faster hash.
def testallhashes():
global h
for hash in hashlib.algorithms_available:
h = hashlib.new(hash)
print(hash, end=' ')
testdata()
testallhashes()
SHA1 We generated 200000 bytes in 2.570000 s 77821 B/s SHA512 We generated 640000 bytes in 6.780000 s 94395 B/s RIPEMD160 We generated 200000 bytes in 2.870000 s 69686 B/s SHA224 We generated 280000 bytes in 3.480000 s 80459 B/s sha512 We generated 640000 bytes in 6.770000 s 94534 B/s md5 We generated 160000 bytes in 1.620000 s 98765 B/s md4 We generated 160000 bytes in 1.350000 s 118518 B/s SHA256 We generated 320000 bytes in 3.500000 s 91428 B/s ripemd160 We generated 200000 bytes in 2.870000 s 69686 B/s whirlpool We generated 640000 bytes in 19.590000 s 32669 B/s dsaEncryption We generated 200000 bytes in 2.580000 s 77519 B/s sha384 We generated 480000 bytes in 6.800000 s 70588 B/s sha1 We generated 200000 bytes in 2.570000 s 77821 B/s dsaWithSHA We generated 200000 bytes in 2.580000 s 77519 B/s SHA We generated 200000 bytes in 2.580000 s 77519 B/s sha224 We generated 280000 bytes in 3.490000 s 80229 B/s DSA-SHA We generated 200000 bytes in 2.570000 s 77821 B/s MD5 We generated 160000 bytes in 1.600000 s 99999 B/s sha We generated 200000 bytes in 2.570000 s 77821 B/s MD4 We generated 160000 bytes in 1.350000 s 118518 B/s ecdsa-with-SHA1 We generated 200000 bytes in 2.570000 s 77821 B/s sha256 We generated 320000 bytes in 3.490000 s 91690 B/s SHA384 We generated 480000 bytes in 6.780000 s 70796 B/s DSA We generated 200000 bytes in 2.590000 s 77220 B/s
Well, no luck. I'll just use a big buffer and have it loop around.
def bigbuffer():
global h
h = hashlib.new("md5")
buf = bytearray()
count = 2**18 // h.digest_size # we want a 256KiB buffer
for i in range(count):
buf += data(i)
return buf
assert(len(bigbuffer()) == 262144) # verify the length
That's for the basics.
class CustomBuffer:
"""
A wrap-around file-like object that returns in-memory data from buf
"""
def __init__(self, limit=None):
self.buf = bigbuffer()
self.bufindex = 0
self.fileindex = 0
self.bufsize = len(self.buf)
self.limit = limit
def readloop(self, i=8096):
dat = self.buf[self.bufindex:self.bufindex + i]
end = self.bufindex + i
while end > self.bufsize:
end -= self.bufsize
dat += self.buf[:end]
self.bufindex = end
return dat
def read(self, i=8096):
if self.limit == None:
return self.readloop(i)
if self.fileindex >= self.limit:
return bytes()
if self.fileindex + i > self.limit:
dat = self.readloop(self.limit - self.fileindex)
self.fileindex = self.limit
return dat
self.fileindex += i
return self.readloop(i)
def testreadcbuf():
f = CustomBuffer(2548)
assert(len(f.read(2048)) == 2048)
assert(len(f.read()) == 500)
testreadcbuf()
def testcbuf(limit=None):
f = CustomBuffer(limit)
l = 0
start = time.clock()
for i in range(10000):
l += len(f.read())
end = time.clock()
speed = l/(end-start)
print("We generated %d bytes in %f s %d B/s"%(l, end-start, speed))
testcbuf()
We generated 80960000 bytes in 0.780000 s 103794871 B/s
That's more in line with what we need.
the FTP stuff
import ftplib
from ftpconfig import config, config_example # ftp credentials, etc
print(config_example)
{'password': 'verylongandcomplicatedpassword', 'host': '192.168.1.254', 'path': '/HD/', 'username': 'boitegratuite'}
def ftpconnect():
ftp = ftplib.FTP(config['host'])
ftp.login(config['username'], config['password'])
ftp.cwd(config['path'])
return ftp
def transfer_rate(prev_stamp, now, blocksize):
diff = now - prev_stamp
rate = blocksize/(diff*2**20) # store in MiB/s directly
return [now, rate]
def store(size=2**25, blocksize=2**20):
values = []
def watch(block):
t2 = time.perf_counter()
values.append(transfer_rate(t1[0], t2, len(block)))
t1[0] = t2
ftp = ftpconnect()
buf = CustomBuffer(size)
t1 = [time.perf_counter()]
try:
ftp.storbinary("STOR filler", buf, blocksize=blocksize, callback=watch)
ftp.close()
except ConnectionResetError:
print("Connection severed by peer")
except Exception as e:
print("Transfer interrupted:", e)
return values
values = store(2**27)
Now trying to show those values !
%pylab inline
import matplotlib.pyplot as plt
import numpy as np
a = np.array(values).transpose()
plt.plot(a[0], a[1])
plt.ylabel("rate (MiB/s)")
plt.xlabel("time (s)")
plt.show()
Welcome to pylab, a matplotlib-based Python environment [backend: module://IPython.zmq.pylab.backend_inline]. For more information, type 'help(pylab)'.
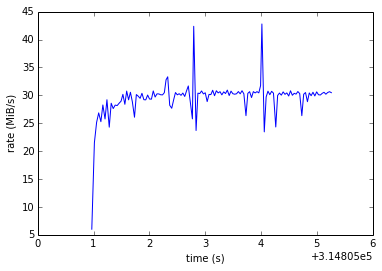
Ok, we have what we wanted: we can measure the write speeds.
Now let's check read speeds.
def reread(blocksize=2**20):
values=[]
verif = CustomBuffer()
i = [0]
def watch(block):
t2 = time.perf_counter()
values.append(transfer_rate(t1[0], t2, len(block)))
dat = verif.read(len(block))
if dat != block:
print("ERROR !!!! Data read isn't correct at block", i)
t1[0] = t2
i[0] += 1
ftp = ftpconnect()
t1 = [time.perf_counter()]
try:
ftp.retrbinary("RETR filler", blocksize=blocksize, callback=watch)
ftp.close()
except Exception as e:
print("Transfer interrupted:", e)
return values
def plot_transfer_speed(data, title):
def average(arr, n):
end = n * (len(arr)//n)
return numpy.mean(arr[:end].reshape(-1, n), 1)
a = np.array(data).transpose()
a0 = average(a[0], max(1, len(a[0])//300))
a1 = average(a[1], max(1, len(a[1])//300))
lines = plt.plot(a0, a1)
#plt.setp(lines, aa=True)
plt.gcf().set_size_inches(22, 10)
plt.ylabel("MiB/s")
plt.xlabel("seconds")
plt.title(title)
plt.show()
rval = reread()
plot_transfer_speed(rval, "Read speed")
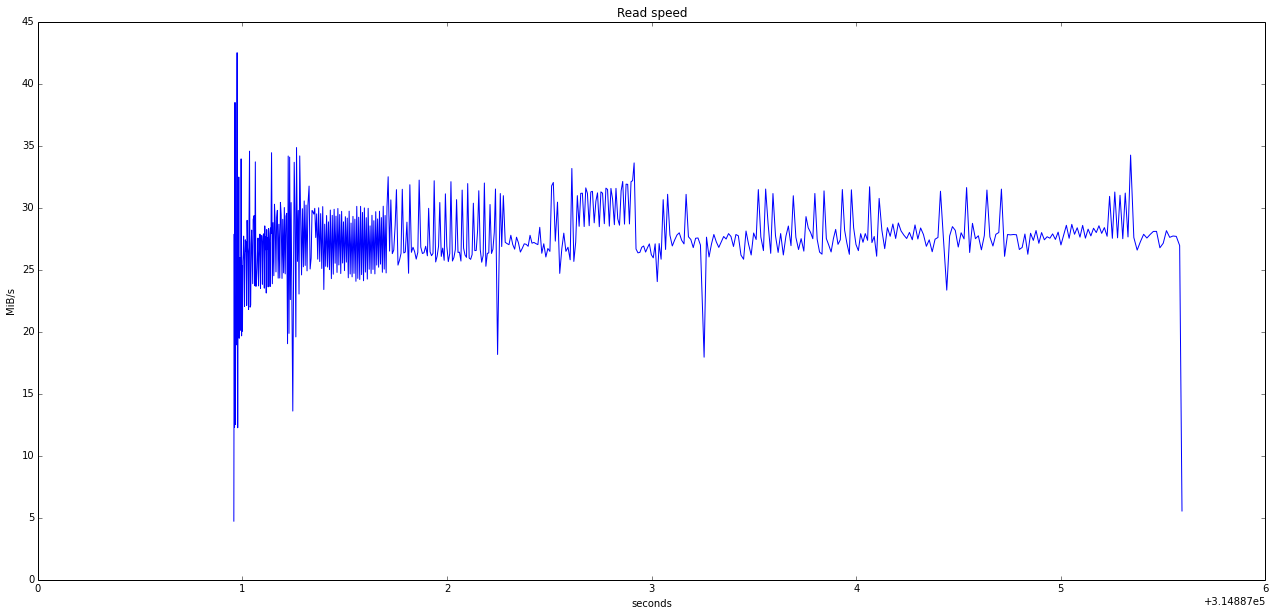
We have all the pieces now. Let's do the filling and plot the data.
# About 230Gio is the effective size of the disk (almost 250Go)
val = store(230*2**30, 10*2**20)
Connection severed by peer
plot_transfer_speed(val, "Write speed")
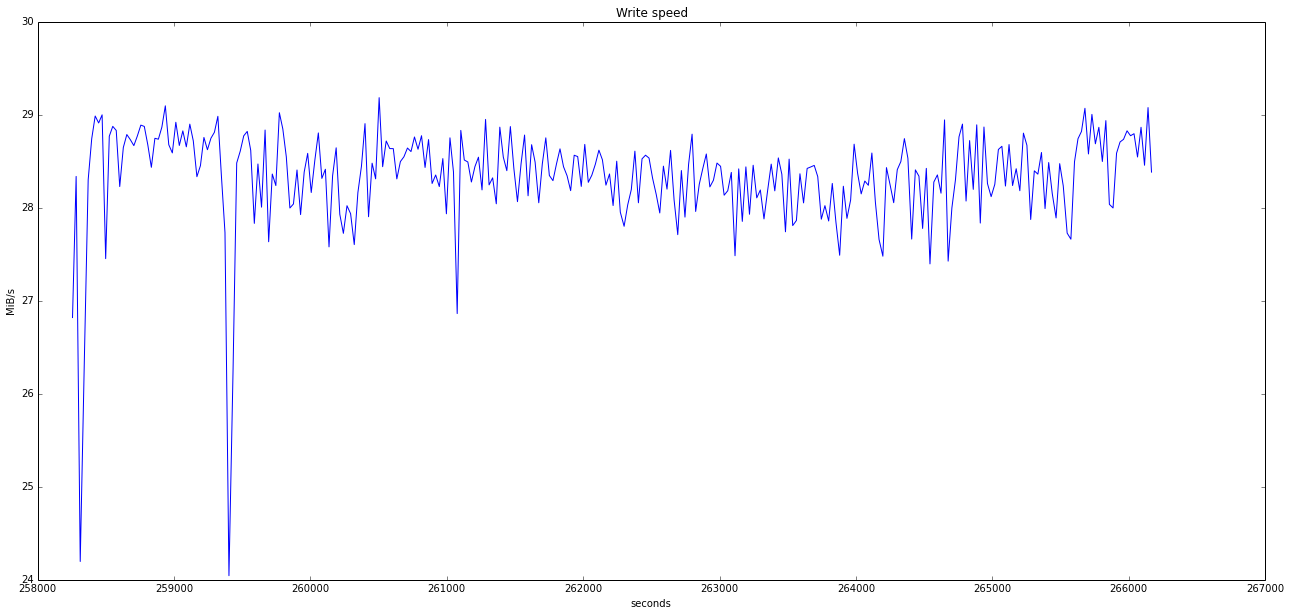
rval = reread(10*2**20)
plot_transfer_speed(rval, "Read speed")
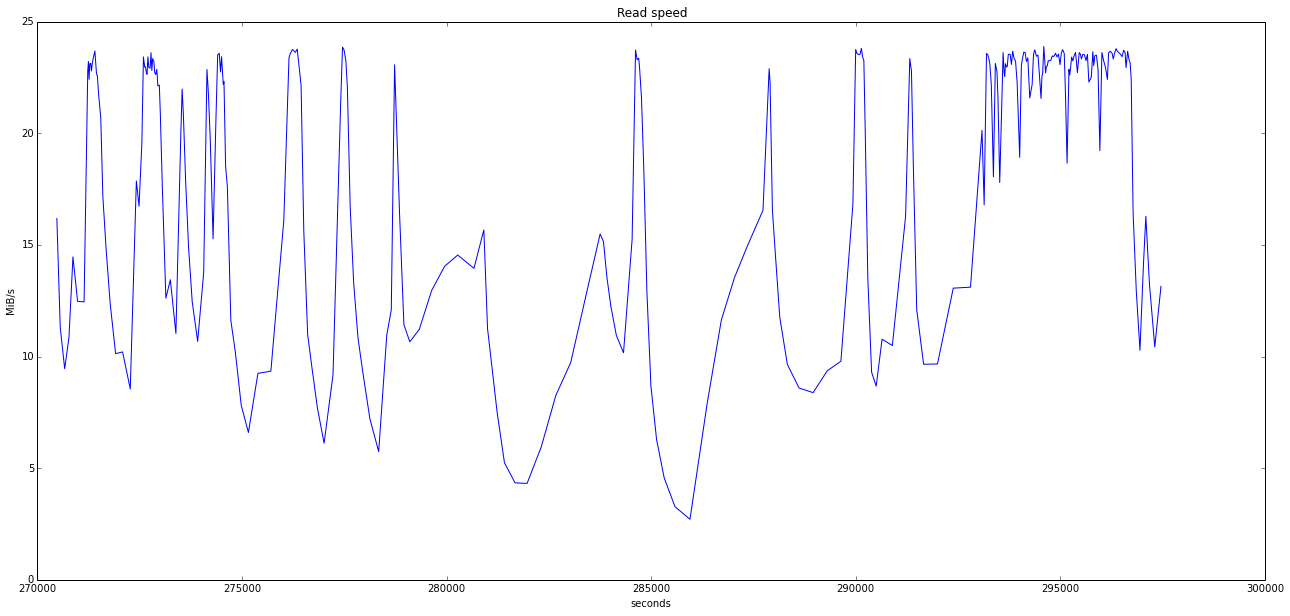
That's it !
We could also plot the read speed against the disk byte index instead of time, which would maybe be more interesting. This is left as an exercise for the reader.
Regarding the data, it's far from what we could get with ATA SMART (using smartctl or skdump/sktest), but it's interesting nonetheless. We can see the read speed falls sometimes, which may be indicative of localized hard drive problem.
What does not appear here is that I've ran the tests multiple times to make sure the data is correct. And both the read and write are long, multi-hour tests.
Also, the simple fact of making a write test may fix an existent problem, by making the disk's firmware aware of the existence of bad blocks. This is amplified by the fact that I ran the tests multiple times.
Finally, what could be improved is having a better way to display a high number of data points. I've used here the average method, which might not show how low the read/write speed can go locally. Maybe displaying the data using a vector format would be better (svg, python-chaco ?).
Regarding the decision to dispose of the hard drive or the NAS, I think I'll keep it for now until it dies, but I'll start putting my data on a external HDD (plugged to the ISP box), and only trust the internal hard drive with low priority stuff like the occasional video recording.