r2con 2018 and r2wars
A security conference in Barcelona
September 08, 2018
I tried something new this year, by going to r2con, a conference dedicated to radare2, a reverse engineering toolkit.
r2con
This conference is one of the most affordable security conference out there. I've used radare2 (r2) in the past, but I don't think I fully understood its philosophy until going there. The radare2 community is really focused on creating the best toolkit for analyzing, disassembling, debugging, reverse engineering software; all while keeping it fully free software.
The training was very interesting, with demos and hands-on experience.
The organization was great, and it was a sleek conference. Many thanks to the organizers.
I've had to install Telegram for the first time to participate in the local discussions, and apparently I wasn't the only one new to Telegram. I've mostly interacted with the radare2 community through IRC before (they have a bridge).
I've met many great people from all over the world; I was honestly surprised how welcoming is the community.
The conference had a single track of talks (all recorded), a CTF (capture-the-flag) game focused on reverse engineering binaries: to crack them, exploit them, etc. with radare2, as well as a little game called "r2wars", on which I spent way more time than I care to admit.
r2wars
In radare2, there's an intermediate language and VM called ESIL. It is used to emulate code, and supports many architectures. r2wars is built on top of r2's ESIL VM, but the rules limit to the following architectures: x86-32, arm-32, arm-64 and mips-32.
In r2wars, two opponents create "bots", short shellcodes, which are executed one after the other, in the same memory space, thanks to ESIL emulation. The goal is be the latest to survive; you must wipe, crash your opponent, or simply wait for your opponent to die by himself by writing or executing at invalid memory.
The ESIL vm is initialized with a 1024 bytes memory space plus a stack (more on that later), and the two opponents are placed randomly in this space. They are executed in round-robin: one after the other, one instruction each. A particularity is that you can have an opponent using a different architecture, since multi-architectures combats are supported: you only share the memory space, not the CPU state (registers). The server makes sure your memory does not overlap your opponents' at launch; afterwards, all bets are off.
You upload the source code of your bot to the r2wars server through a web interface ; the server software uses rasm2, the radare2 assembler to build your bot, it launches radare2, initializes ESIL, then launches 1v1 matches in a tournament, to determine the winner.
My bots
I've dumped the source code for all my bots on github (spoilers!).
Naive approach
My very first idea was to create a self-replicating bot that would survive forever by copying itself in a loop. It took me long time to build as I was getting used to the aarch64 assembly (I mostly have experience with aarch32 and thumb).
One of the first hurdles would be that the rasm2 assembler is still quite incomplete. It does not support all arm64 addressing modes for the branch instructions, it does not support load/store pre/post-indexing; it does labels in a naive way. For example, if you give a very short name to your label (say, 'x'), it will replace all occurrences of "x" in the program; which might be an issue in arm64, since the registers are named x0 to x30.
One of the goal of the r2wars competition was to improve rasm2 and ESIL emulation in radare2. I looked at instruction encoding, finding a few references in addition to the official manual, but I couldn't figure out the post-index address encoding for ldp in a short-enough time to be useful for the competition, so I moved to the gnu assembler included in the fedora package binutils-aarch64-linux-gnu. The binary code is then converted to .hex directives for rasm2.
Once I did that, I discovered that ESIL emulation in radare2 was much more complete, and that the code I wrote behaved as expected (well, minus my bugs).
At first I attempted to make use of "combined" instructions like csel, cbz, or ldp/stp; I've mostly kept ldp/stp afterwards, since they are the instructions which can read and write the most data that at once: two 8 bytes registers, with the option to modify/increment the addressing register at the same time with the so-called pre-index (modify the register before the load/store) and post-index addressing mode (modify it after the load/store). This allowed, when repeated, to do the most damage. This is my first bot:
adr x0, -16
add x1, x0, endprog
add x5, x1, endprog
cmp x5, 1024 - 16
csel x1, xzr, x1, gt
add x5, x1, endprog
add x4, x1, 16
looprog:
ldp x2, x3, [x0, 16]!
stp x2, x3, [x1, 16]!
cmp x1, x5
b.lt looprog
br x4
endprog:
nop
It's very naive, but it works. It copies itself in a loop, and wraps at 1024 bytes. It should never die when left a alone. The issues are numerous, but the biggest ones are that it's simply too slow, and too big, clocking at 48 bytes of useful instructions. I submitted it once, but never used it in a competition, replacing it with a better one.
Simplicity
Once I managed to build and run the official r2wars server (you need an official version of Mono for that, not the distro versions which are too old), I started writing other bots to have them compete with each other, before the official matches. I wrote a few variants of this bot:
adr x0, 68
adr x1, -4
loop:
stp x0, x2, [x1, -16]!
stp x1, x2, [x0, 16]!
b loop
This bot will first get its own address + 68 (to be at the end of the reserved space by r2wars), and then will start writing groups of bytes in the up and down directions, until it died by reaching invalid memory.
And most of those simple bots weren't statistically worse than the original bot. As it was already 3am before the competition started, I decided to call it a night, and submit my initial naive approach.
Insomnia
But. I just couldn't sleep. I had so many ideas, so I got up and wrote this one quickly:
adr x0, start
mov x3, 1008
ldp x1, x2, [x0]
stp x1, x2, [x3]
br x3
start:
stp x0, x4, [x3, -16]!
stp x0, x4, [x3, -16]!
stp x0, x4, [x3, -16]!
b start
This one copies it payload at the end of the arena in only 4 instructions, jumps to it, and then the payload will just overwrite all bytes at a significantly higher rate than the other ones. I wasn't sure it would be more efficient, but I went to sleep for real.
The following morning, I ran the simulations again, and this new one was completely thrashing the others. I decided to submit it, and it was the one used in the first tournament.
The fights
It didn't fare so well during the first iteration of the tournament. It was the only arm-64 bot, mostly against x86 bots, and I didn't understand why, but it arrived in 5th of 8 position. Not too bad.
I went on to work on my next idea: a single-instruction bot, providing a much slimmer target against non-linear writes, and always writing its next instruction. It needed to be slow, to not die quickly, so I had to write only 4 bytes at once. So I changed from the wide-store stp, to the smaller str. It supported the pre-indexing addressing mode, so it could work.
But that's when I found my first ESIL bug. It turned out that ESIL arm64 emulation only implemented the pre-indexing addressing for str. I looked more into the code, and found that the ESIL VM used polish-notation instructions. It looked complicated, but I tried to understand how stp pre-indexing was implemented. I got derailed, so I missed the next r2wars tournament iteration, and didn't upload any update !
But, magically, this time, my bot had it much better. Either the other opponents evolved to algorithms that were weaker against this strategy, or the new opponents gave me more points, or simply the randomness of the initial position was more favorable; but anyway, I arrived in 3rd position this time. I got a prize for being in the top 3, and was very happy. But this was only the beginning.
Stack escape
I noticed that some opponents would continue on living after I had overwritten them. How ? They were running x86-32 code. And it turns out, I was mostly writing zeroes; which are interpreted as valid x86 instructions. This architectures has simply too many valid opcodes.
I also noticed that one of the x86-32 opponents, zutle, had a sudden weird bug: it was executing code at 0x01780xxx address. What sorcery was this ? Isn't the arena between 0 and 1024 ? It turns out, that in ESIL, that is the default initialized stack address. And it's executable! Time for a new bot.
The idea of this bot, was to copy its 4-instructions payload somewhere on the stack, live there, and wipe the whole arena from there, in a loop:
adr x0, start
mov x3, 0x7ff0
movk x3, 0x0018, lsl 16
ldp x1, x2, [x0]
stp x1, x2, [x3]
mov x5, 0
neg x0, x0
mov x1, x0
br x3
start:
stp x0, x1, [x5], 16
stp x0, x1, [x5], 16
and x5, x5, 0x3ff
b start
And this time, it would only write 0xff bytes (well, mostly), to prevent the x86 valid 0x00 opcodes. The strategy is otherwise the same. It starts at 0, and overwrites the whole arena with a post-indexed stp, and the and here checks when the end is reached (a much better idea than my initial csel-based naive approach). And it worked well, in my simulations (with r2 and r2wars from git).
But not in the tournament. In the tournament, it turns out that the post-index in the stps were simply ignored. So the bot escaped to the stack, and then basically waited at the beginning of the address space for the opponent to come being overwritten. Sometimes it would work, sometimes the opponent would kill himself, and sometimes, it would run forever. Well, not forever, since the game has a timeout of 4000 cycles (already reduced from 8000 cycles in the first round). After the timeout, a draw would happen.
The timeout shouldn't be an issue, since the timeout usually happens in less than 30 seconds... for an x86 bot. It turns out, ESIL arm64 emulation was much slower than x86, and the timeout felt like it was 10 times longer (I didn't measure). My bot was still the only arm-64 fighter at this stage (there was one arm-32, and one mips, the rest was x86-32), so I was responsible (well, with the ESIL bug in the r2 version of the organizer) for a VERY long tournament. It took ~1h15m instead of the usual ~7m.
Of course, I wasn't the only one to have this idea. Konrad had the same idea as he entered the game, and wrote an x86-32 bot with this strategy; our bots didn't meet, so we had a draw. His bot didn't have a buggy emulation, so he had less draws and arrived first. I was second, so I got another prize! Yeah !
Special mention to Dimitris who managed to be third here with a strategy that didn't use any stack escape. And he had more wins than my bot ! (I won because I had more draws).
Of course, this very long tournament iteration triggered a reaction from the organizers, and execution out of the main arena had to be forbidden. No more stack execution.
Ending
So, with the my last strategy not working anymore, I re-uploaded my first competing bot, and called it a day. I had already won top-3 twice, and I didn't need any more prizes. I tried other strategies for a while, but didn't submit them and came back to fixing ESIL emulation of str pre-index and post-index addressing. I sent a pull request to radare once it somehow worked, and went on to follow more conferences.
The next round saw my strategy being relatively bad, with place 7 over 12. Fighting bots of different architectures is sometimes a disadvantage: x86 has more compact instructions, it has an instruction to dump all registers permitting very wide writes, etc.
I still took the opportunity to update it before the last round to write 0xff instead of 0x00 to improve the win-rate against x86 bots:
adr x0, start
mov x3, 1008
neg x5, x0
mov x4, x5
ldp x1, x2, [x0]
stp x1, x2, [x3]
br x3
start:
stp x5, x4, [x3, -16]!
stp x5, x4, [x3, -16]!
stp x5, x4, [x3, -16]!
b start
I really want to thank the organizer of this tournament, skuater. He couldn't be present at r2con since he missed his flight, but still streamed the tournament, reacted to bugs we found, provided very nice support over Telegram, told us when our bots weren't building, etc. Kudos !
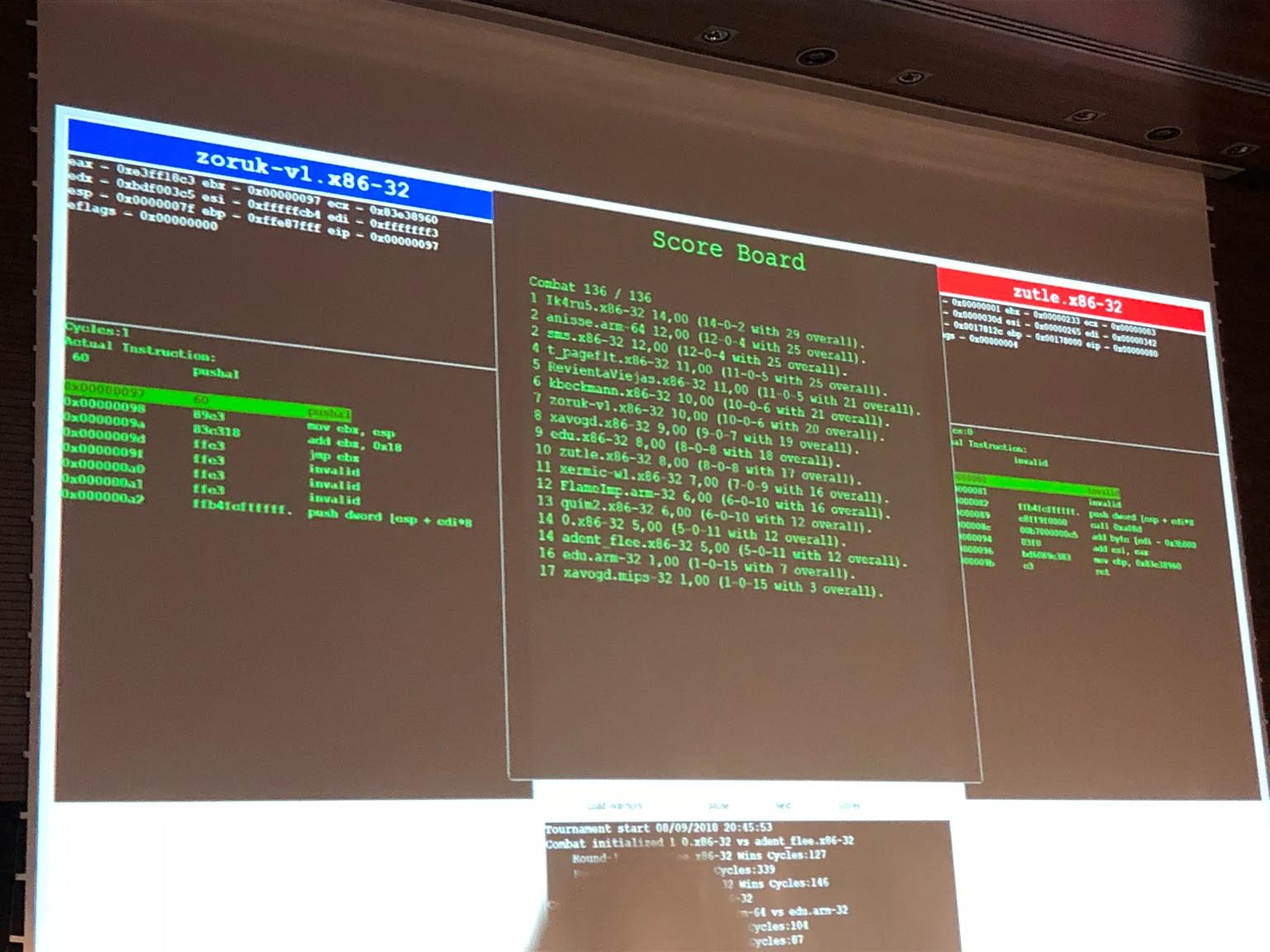
I didn't get to watch the last tournament of r2wars because I had to leave early. As I finish writing these lines, my plane lands in Paris. I open my phone, to see that my PR was merged. And that Konrad just sent me this picture, showing the results of the last r2wars tournament: