December Gears emulator update
Debugging a VDP is fun !
January 04, 2023
I wrote here about how I'm writing an emulator. How has it progressed ?
Fixing a rendering bug with backgrounds
In November I wrote on mastodon how I was tracking down a rendering bug.
To track down this issue with weird data on screen, there was already too many messages, so it was very hard to find anything with printf debugging. So I added a border to every bg/sprite character, and encoded the pattern number in the border color. I didn't know if it would work but it looked fun:
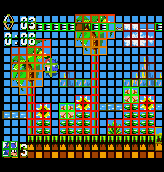
I then slightly changed the encoding in border color (zoomed for visibility):
After that, I continued working on unrelated things. I took some time to play the game a bit more in the emulator, which finally gave me an epiphany. Once I had identified the issue, fixing was fairly straight forward. It was missing wrapping in x.
This is because you can imagine the background in the Game Gear VDP as a torus: on this torus, the viewport (the game visible area on the LCD) is a window showing the actual content, controlled by scroll offsets in X and Y.
Of course in memory, this "torus" is just a simple and straightforward memory buffer. So implementing it means wrapping around when the viewport reaches a border of the memory buffer.
Wrapping in Y was working already because rendering is done line-by-line and once the proper line is selected, it stays the same.
Wrapping in X simply wasn't done, so once a border was reached, instead of continuing rendering on the same line, we actually went to the next line ! And it also means that sometimes a line would be rendered that should never have been on screen, hence the weird looking data.
I'll let you compare this screenshot with the previous one:

And a final note: I was focusing entirely on the wrong thing here, only seeing the weird data, and not the other rendering bug completely shifting the background screen by 8 pixels.
In the end, the fix was relatively simple.
Implementing missing features
Off-by-one error in sprite rendering
This one was found by looking at other emulators and noticing something weird in Sonic's splash screen :
 (Rev 1).127-off-by-one.png) Before |
 (Rev 1).127.png) After (correct render) |
Can you see it ?
Here, I added a line to let you see it more easily:
 (Rev 1).127-off-by-one-line.png) Before |
 (Rev 1).127-line.png) After (correct render) |
This is due to the way the coordinates are handled for sprites. They should be offset by one pixel (compared to what I did before) ! Here is another example, zoomed in on Sonic's hand in the Press Start screen:
 (Rev 1).385-off-by-one.png) Before |
 (Rev 1).385.png) After (correct render) |
Background priority over sprites
On the Game Gear VDP, background tiles have a priority bit that allows them to be in front of sprites. This is very useful to give an impression of depth. Usually it's done so that one color from the background is not above sprites. So blending looks seamless. When rendering the background, the emulator should keep track of patterns that have the "PRIO" bit, and render them always in front of sprites (except for color code "0"). Here is a still from Sonic Triple Trouble before and after implementing background priority:
.60-S-1500-s-635-nobgprio.png) Before |
.60-S-1500-s-635.png) After (correct render) |
In this frame the trees are part of the background, and have the PRIO bit set. So they should be rendered over sprites: Sonic, but also the game status in the upper left corner !
Priority between sprites
Here is Sonic 1's first frame:
|
Before |
 (Rev 1).3.png) After (correct render) |
What happens here ? Surely the first one is the correct one ? It left me just as confused as you when I looked at other emulator's rendering of this first frame. I even checked on a real Game Gear just to be sure!
The 64 sprites available on the Game Gear/SMS VDP should be rendered one by one, in the order they appear. The first sprites have priority over the later ones. This means the later ones should NOT be rendered if another sprite was rendered on a given pixel (except for transparent colors…).
So what happens on this frame ? Luckily the debug mode I developed earlier is still in the code base behind a config flag that is easy to toggle:
 (Rev 1).3-pattern-debug.png)
The game uses higher-priority blank sprites to hide the rest of Sonic ! (probably from a re-used routine). This is so that in the animation where the Sega logo appears, it looks like there's a magic line that makes everything appear. And Sonic's feet and hand would go over that line ! So they were hidden by developers by putting blank (but not transparent) sprites before Sonic.
A remaining map bug
There might be plenty of remaining bugs, but here is one I found in Sonic's map screen after I implemented background priority:
 (Rev 1).3-S-3-s-60-S-320-actual-noprio.png) Before (bad) |
 (Rev 1).3-S-3-s-60-S-320-actual.png) After (still bad, but worse) |
The current level line and number of lives disappeared ! Why ? I don't know !
It seems the background priority are incorrectly set. I have no idea why it does this.
After I saw this I thought I caused some kind of regression, so I added a test framework to generate frames and compare them with a "good" render to prevent regressions. This is how most frames in this section where generated, and why the filenames have a weird naming. You can check how it works in the repo and the test frames.
But it's not the only issue for this frame ! Here is how this frame should actually look, if we check how the map is rendered with another emulator:
|
How it looks like currently |
 (Rev 1).3-S-3-s-60-S-320-target.png) How it should look like |
I'm not sure I'll try very hard to fix this one. I'll probably go slowly and think about it in the background, waiting for the right epiphany.
Update: I wrote about how I fixed it.
This article →